Layer 2 Networking Pseudo Redundancies
Premise
I’ve seen many production networks that rely on layer 2 pseudo-redundancies through the core, and I’m here to explain why such designs are unnecessary, often dangerous, and how they can be improved. This article assumes an understanding of the OSI model, the most common protocols at layers 2 and 3, and the common “Cisco campus” Core/Distribution/Access network model.
This article aims to cover the following:
- Collapsed core and L2 core/distribution networks
- Limitations of common L2 HA tools – VSS, STP
- L3 alternatives
Layer 2 HA Scenarios
Consider the following common collapsed core environment, and the protocols at play to provide redundancy.
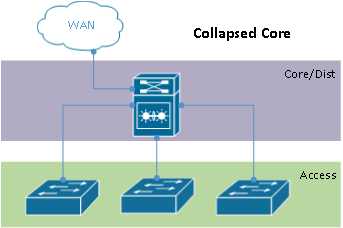
- Core uses Cisco VSS, StackWise or similar shared control plane redundancy mechanism
- Some or all VLANs span all access switches through L3 switch core
- Spanning-tree (Classic STP, Rapid-STP, or MST) handling failover between physical access-core links
- Little or no dynamic routing use
- “Distribution” layer may be created to support campus expansion
Let’s touch on a few points that may seem like advantages to an engineer jumping into such a network.
The single shared Layer 2 domain allows for an “any user, any subnet, anywhere” approach to provisioning new ports and access for your users and systems. A user moving between physical points, departments, or switches in your campus or network does not mean re-addressing or re-configuring access rules, software, etc.
Having minimal routing protocol usage can be attractive to some – as all of the tunable knobs of OSPF, EIGRP, and BGP can be a little overwhelming. When a new port or subnet is needed, an SVI in the Layer 3 core can easily be configured, and a new VLAN trunked where needed.
VSS and other shared control plane solutions create a single logical switch. This has the apparent benefit of reducing administrative burden by having only a “single switch” to manage, and gaining physical hardware redundancy without using more complicated (administratively, anyway) protocols such as HSRP, GLBP, and dynamic routing.
Limitations of Common Designs
When you look beyond some of the key points above, you find some serious issues with collapsed core and shared control plane technologies in the core. Consider the diagram above with a single VSS pair in the collapsed core. Although the core switch and it’s connected infrastructure can survive a single physical hardware failure (up to a full VSS chassis), assuming all connected devices are dual homed using port channels, the entire network can be interrupted by a single “logical” failure, human error, or software bug. While VSS pairs can make an excellent edge or access layer switch, you should carefully consider the risks involved before deploying them in a core setting without other redundancy mechanisms.
In addition to increasing the risk of large-scale failure, solely relying on shared control plane redundancies also reduces flexibility in routing and traffic engineering. Switches configured in VSS or StackWise pairs maintain a shared routing table, routing processes, and make the same routing decisions.
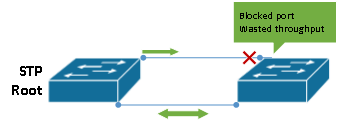
Wasted bandwidth can be another issue when relying on Layer 2 transport and Spannning Tree failover from core to distribution or access network segments. When relying on any STP protocol (Multiple Spanning Tree with properly configured instances being the exception) for link redundancy, one or more links in a bridge must operate in a blocked state by design – reducing total available bandwidth of the topology.
Finally, STP (and VTP, if you choose to run it) is often classified as a dangerous and slow protocol. By design, every STP speaking bridge in a tree participates in Root Bridge election and exchanges bridge protocol data units (BPDUs) to determine who the root bridge is, where it’s located, and what paths need to be blocked. All it takes is one misconfigured switch inserted into the network to cause wide-sweeping failures or performance issues, which are often cumbersome to troubleshoot. If you’ve never had to troubleshoot spanning tree issues during a network failure, count your blessings!
Layer 3 Alternatives
Route everything – many networks and network engineers would benefit from abandoning the idea that any modern application actually requires layer 2 adjacency. Almost any broadcast domain spanning more than one device hop, or two network hosts total, can be eliminated and routed over without negative impact to the applications traversing the path. The most common exception to this rule is virtual machine migration traffic such as VMWare vMotion; technologies such as Cisco Overlay Transport Virtualization exist for remedying these exceptions.
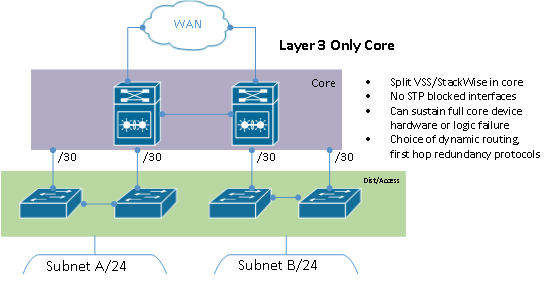
Moving to a layer 3, route-centric design, also provides more options for protocol selection in how you transport your traffic from one network segment to another. Most common small and medium size networks will be sufficiently supported with basic OSPF or EIGRP implementations while larger enterprise and service provider networks will often rely more heavily on BGP and IS-IS. Your choice of protocols should be influenced by administrative experience, networking vendors involved, and your requirements for scale.
Proper use of first hop redundancy protocols such as HSRP, VRRP, and GLBP can also provide hardware redundancy at the first hop gateway much like VSS and StackWise – without the inherent risks of putting so many eggs in one proprietary basket.
Finally, depending on your route design and configuration, relying on layer 3 protocols for redundancy and transport allows for load balancing traffic across multiple paths. Equal cost and unequal cost load balancing can allow for full utilization of all network links without sacrificing ports and hardware for failover/blocked paths.
Summary
The topologies, protocols, and designs mentioned above are all only examples of tools that should be readily available in every networkers’ toolbox. Hopefully, this article has sparked some ideas that will lead to building a more redundant, better-performing network.

