
Webinar Recap: How to Stop Cybersecurity Threats with Managed EDR
On June 17, 2026, DataYard and Huntress hosted a live


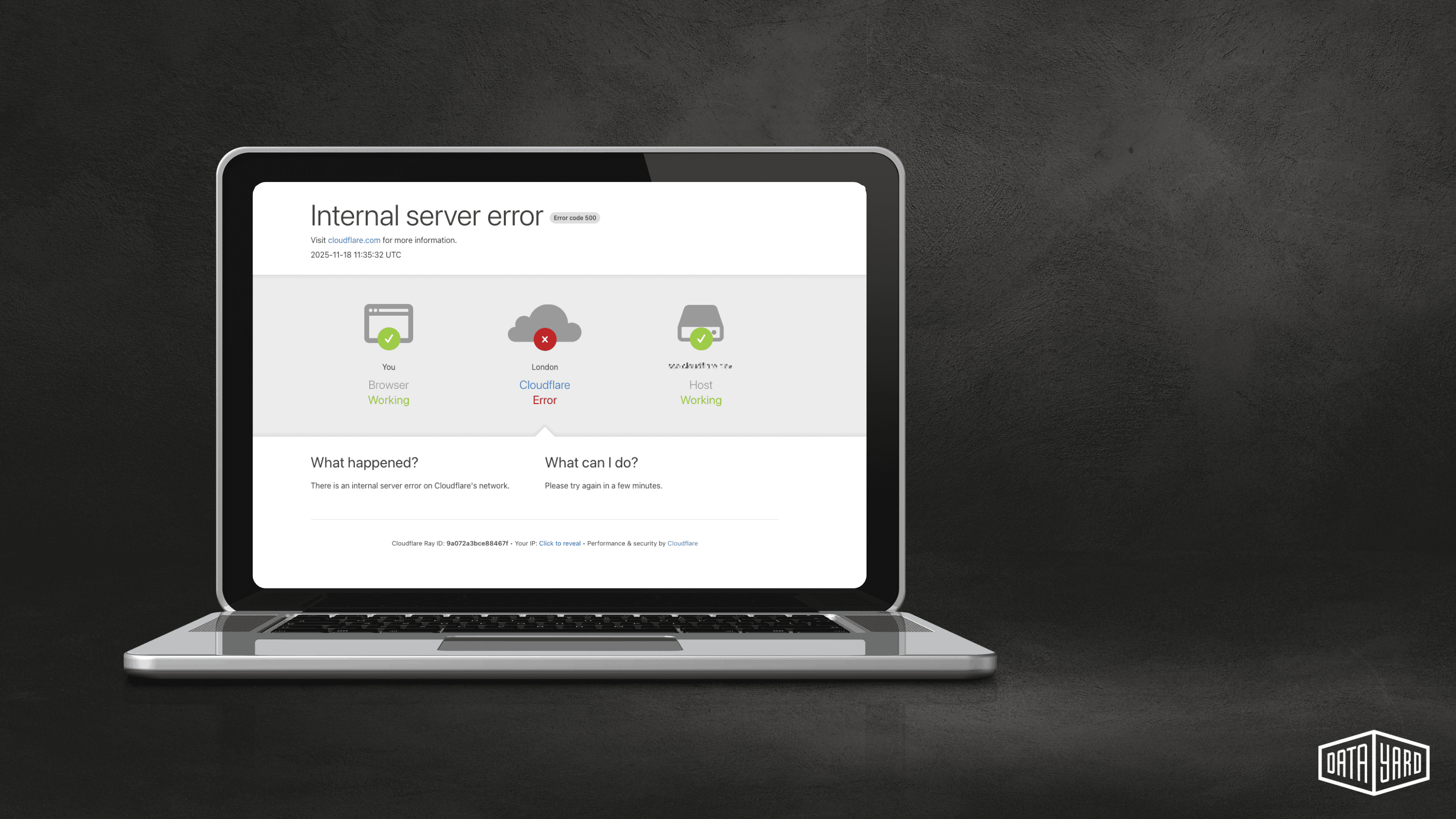
The incident impacted core services — CDN delivery, DNS, WAF, Access, caching (Workers KV), and the Cloudflare Dashboard — resulting in six hours of widespread disruption.
While early diagnostics suggested a possible malicious attack, Cloudflare later confirmed the root cause was internal — not a security event, but a misconfiguration error. Services were restored gradually over several hours, but impact varied by region and setup.
(Source: Cloudflare Blog – November 18 Outage![]()
![]() )
)
If your company relies on Cloudflare for DNS, CDN, or edge security services — directly or through a vendor — you likely saw immediate operational impacts that affected customers, users, and revenue.
For many organizations, the outage was a wake-up call about centralization risk: when core DNS and edge services go dark, sites and services worldwide can suddenly become unreachable. If you’re unsure whether your website or third-party tools depend on Cloudflare, a quick audit can reveal single points of failure and help prioritize fixes.
Even if your site didn’t go down completely, you may still have been affected.


On June 17, 2026, DataYard and Huntress hosted a live

As Endpoint Detection & Response (EDR) becomes more widely discussed

Anthropic’s newest AI model, Claude Mythos Preview, has been generating